This Week's Play: Voice-Invocation
This Week's Play: Voice-Invocation
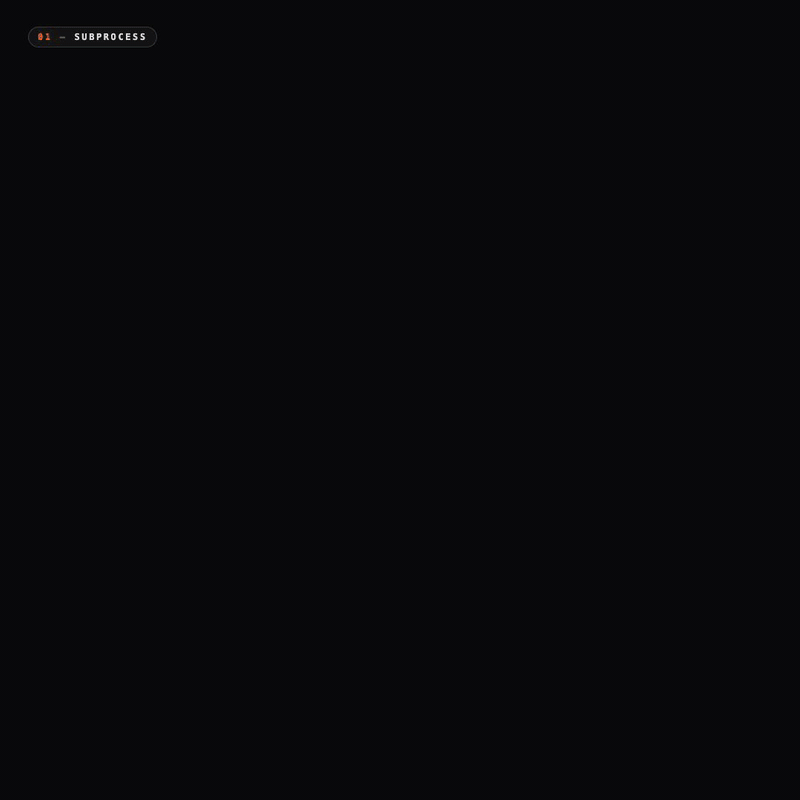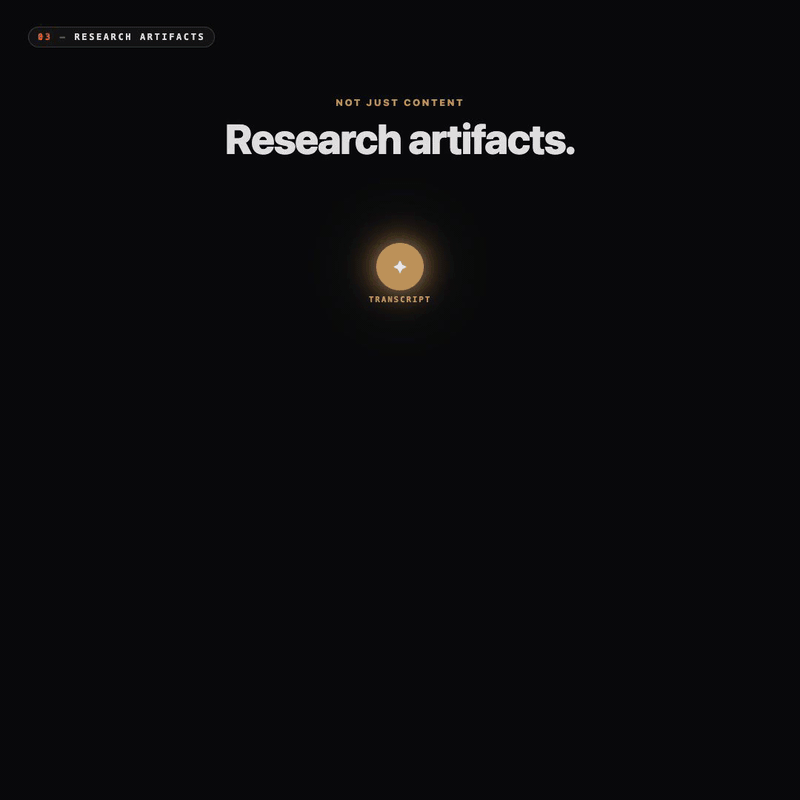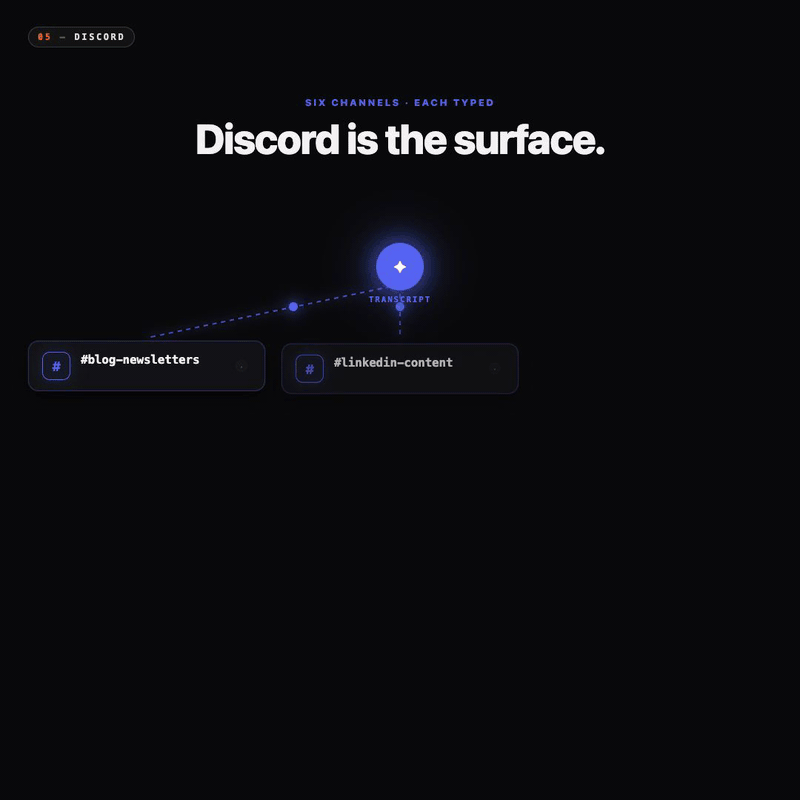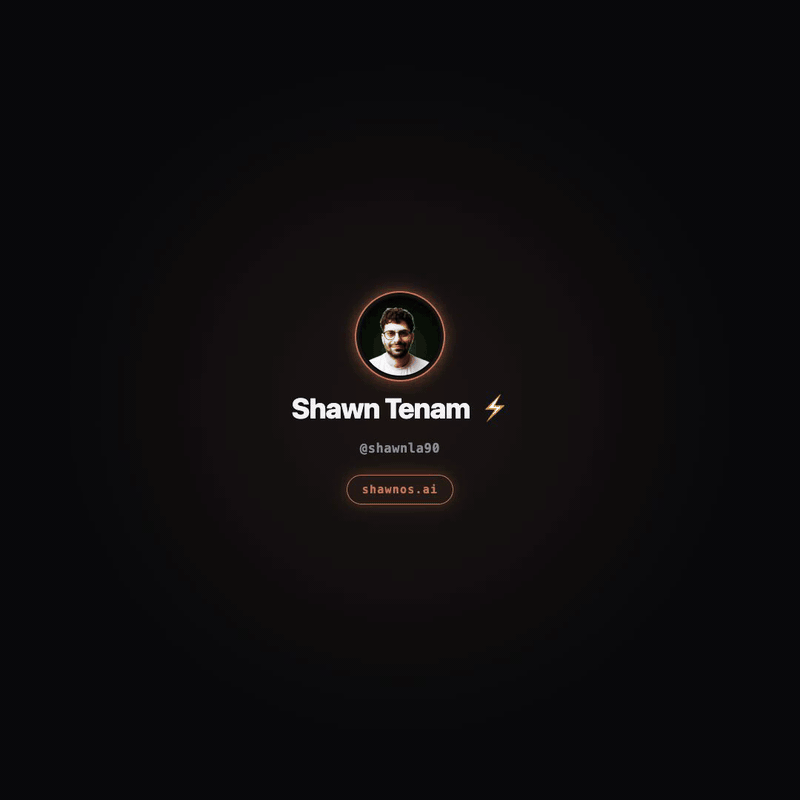
Every call becomes content, todos, signals, and pain points. Each output funnels to its own Discord channel for review.
Newsletter #4. This week's play. Every call now ends with six different things waiting in Discord. A blog draft. A LinkedIn post. An X thread. The todos committed to mid-conversation. The pain points the other side surfaced without realizing it. The signals about where the market is actually moving.
AI is doing the surfacing. The choosing is still mine.
With AI and content, the point isn't to generate more. The point is to help build the narrative. Surface the signals. Surface the pain points. Catch the post that would have been written next anyway, before the exact phrasing of what was just said gets lost.
Create once. Distribute anywhere.
One transcript becomes a blog post, a Substack draft, a LinkedIn newsletter, a feed post, an X thread, and optional Reddit drafts when the conversation maps to a sub. Plus the todos. Plus the pain points. Plus the signals. Plus a voice-drift report telling me whether I sounded like myself in the conversation, or whether I drifted toward marketing speak somewhere in the middle of explaining the product.
Six different reads of the same thirty minutes. None of them is a summary.
Here's how it actually runs. Fireflies records the call. A launchd cron picks up the transcript on a schedule. A custom script fires off subagents in parallel. Each subagent reads the same transcript with one specific job. One drafts the blog post. One drafts the LinkedIn post. One scans for pain points. One looks for signals. One pulls todos. One runs voice drift. The pack lands in Discord about four minutes after the call ends.
Each output funnels to its own Discord channel
Blog drafts in blog-newsletters. Standalone LinkedIn posts in linkedin-content. X threads in x-posts. Pain points get their own channel. Signals get their own channel. Todos get their own. The voice-drift report goes to voice-drift.
Six channels for one call. Each one a typed mailbox holding one shape of context. Open Discord and the right shape is already waiting. Blog channel for writing mode. Signals channel for positioning work. Pain points for product review.
Why Discord at all
Claude Code is non-deterministic. Run the same prompt twice and you get two different drafts. That's a feature when I'm exploring. It's a problem when I'm shipping under my own name.
I can't push non-deterministic output directly to a CMS. I can't push it straight to LinkedIn. I need a surface between "the model generated something" and "this goes live."
I build in the terminal. I audit somewhere else. Localhost dashboards work for one machine. Claude Cowork works inside Anthropic's surface. Discord works because it's already on my phone, channels are typed, webhooks land instantly, and the embed carries enough context that I can read the draft from anywhere and type a verb back.
The terminal builds. Discord audits. Subprocesses are the bridge.
Modularity is the edge
Every channel is a webhook. Every subagent is a markdown skill file plus a Python script. Every transformation is something I can adjust on a Tuesday and ship before Wednesday's first call.
Routing changes are cheap. Signals should go to a different channel? Move them. Want a competitor-watch subagent that flags every named competitor in any call? Add one. Voice drift should include cadence telemetry, not just phrasing matches? Update the principles file. Each change is one webhook drop in Claude Code, one new skill markdown file, and a git commit. Thirty seconds. Version-controlled. Reversible.
Skillify it once and the skill runs in the background. The webhook is one line. The state machine lives in a SQLite file. The whole pipeline is small markdown files and Python scripts. Phone-readable. Editable from anywhere.
It costs zero per call
The pipeline runs claude -p --model opus as a subprocess. That CLI binary inherits my Claude Code Max auth, which means every call bills against the subscription I already pay for, not against the Anthropic API. Three to five dollars of API tokens per 30-minute call collapses to about zero marginal. One trap. The -p runner has to be the CLI binary, not the SDK. SDK calls bill the API. The economics flip on which entry point you import.
Listening is the product
Clearbox launches in seven days. The thesis under it is the same thesis under this pipeline. The signal I want is the one in the conversation, not the one my dashboard thinks it sees. Voice-invocation is the formalized version of letting my meetings tell me what to ship. Same loop produced Clearbox. Every conversation I had pointed at the same product before I had a name for it.
Same weekend I shipped this pipeline, I started streaming as shawnbuildsit on Twitch. OBS, Aitum, multistream to a couple platforms. Building a Hollow Knight KillCount dashboard with Claude Code on stream. Different brand, same shape. Stop performing the work in private and posting the highlight reel later. Broadcast the work itself.
Create once. Distribute anywhere. AI surfaces. I choose. Discord is where I review. Subprocesses keep it free.
That's the play.
Each chapter in GTM Coding Agents is a play. New play every week. The repo at github.com/shawnla90/gtm-coding-agent has 13 published chapters today. Voice-invocation ships as chapter 14 on Wednesday with the full disclosure. Scripts, routing config, subagent prompts, SQLite schema. Until then, the existing chapters run the same loop on different plays. HubSpot outbound, voice DNA, CLI vs MCP, signals reveal, and nine others. No email wall, no course upsell. Fork it.
shawn ⚡